[翻译]在生产环境中分析 Python 代码性能
原文标题为 Profiling Python in Production - How we reduced CPU usage by 80% through Python profiling,作者 Eben Freeman,发表于 Nylas 官方博客。
我们最近将整体 CPU 使用率降低了 80%。使这件事得以完成的关键技术,是一种我们能够在生产环境中进行轻量级性能分析的策略。这篇文章描述了我们使用的测量方式、权衡的因素,以及一些可以用于优化你自己应用的工具(包括代码)。
背景
Nylas 是一个提供用于集成电子邮件、通讯录、日历的 API 的开发平台。其中的核心是一项我们称之为 Sync Engine 的技术。这是个大型 Python 应用(大概 3 万行代码),处理通过 IMAP、SMTP、ActiveSync 等其他协议进行的同步。其代码已经在 GitHub 上开源,并有坚实的社区基础。
我们将其作为托管的基础设施运行,为全球的开发者和企业提供服务。它们的产品依赖于我们的在线保证和及时响应,所以整个系统的性能占有很高优先级。
不计量就无法完成
优化始于测量,但是性能分析并不只有一种方式。在小规模时使用基准测试进行分析,在大规模时使用正式环境进行性能分析,这是很重要的。
例如,当一个新的邮箱被添加到 Nylas 平台时,邮件被尽快同步是很必要的。为了优化这个过程,我们需要知道同步策略和优化措施会如何影响同步最开始的几秒。
在本地设置好测试环境并添加一些测量代码之后,我们可以拿到程序的函数调用图。只需要通过 sys.setprofile() 来拦截函数调用就可以了。为了更好地查看在这其中发生了什么,我们把数据从调用图中导出成特定的 JSON 格式,就可以用 Chrome 开发工具内置的可视化工具加载。现在我们可以看到精确的函数执行时间线。

动态
这种策略对于应用程序某一部分的基准测试是很不错的,但要分析大型系统的总体表现就不合适。对函数调用进行测量会造成其执行速度显著下降,同时会产生过多的数据,因此我们不能直接将这种方法用在生产环境中。
然而,在人工的基准测试中要精确重现生产环境中的低效情况是很困难的。同步引擎的负载情况各种各样:我们同步的账户有大有小,其中有各种等级的活动,并且策略随邮件服务提供商变化。如果测试无法准确反映真实世界的负载的话,我们做的优化都是无意义的。
针对这些缺点,我们的解决办法是,添加一种可以持续地在生产环境中运行的轻量级测量手段,并设计一个系统将测量到的数据卷动到易于管理的格式和大小。
这种策略的核心是一个简单的基于统计的分析器——一段周期性对调用栈进行取样,并记录其内容的代码。这种方法在测量的粒度上有所欠缺,并且是非确定性的。但代价也较低,是可控的(调整采样间隔即可)。较粗的采样间隔就可以发挥作用,因为我们是要确定造成性能下降的最主要因素。
很多库都有这方面的实现,但是用 Python 的话,一个堆栈采样器只需要不到 20 行就可以写好了:
|
|
调用 Sampler.start() 会在一定时间(由 interval 指定秒数)后触发 Unix ITIMER_VIRTUAL 信号。大体上就是会循环调用 _sample 方法。
当信号被触发时,这个方法保存应用的调用栈,并持续记录我们对同一个堆栈采样的次数。采样越频繁的堆栈就对应着我们的应用耗时最多的那部分代码。
维持这些堆栈计数所消耗的内存在可接受范围内,因为应用只执行这么多不同的帧。内存用量也是可控的,如果需要的话,可以定期将调用不那么频繁的堆栈的计数清除掉。在我们的应用中,实际 CPU 消耗明显可以忽略不计:
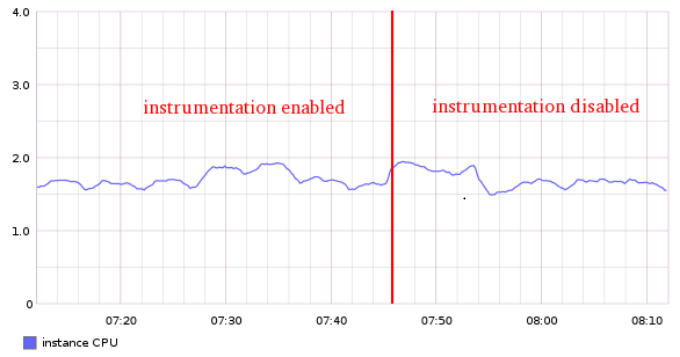
在应用程序中添加好测量代码后,我们将每个 worker 进程的性能数据通过 HTTP 接口暴露出来(参考代码)。这样我们可以对生产环境上的一个 worker 进程采样,生成性能火焰图,可以简洁地说明时间都消耗在了哪里:
|
|
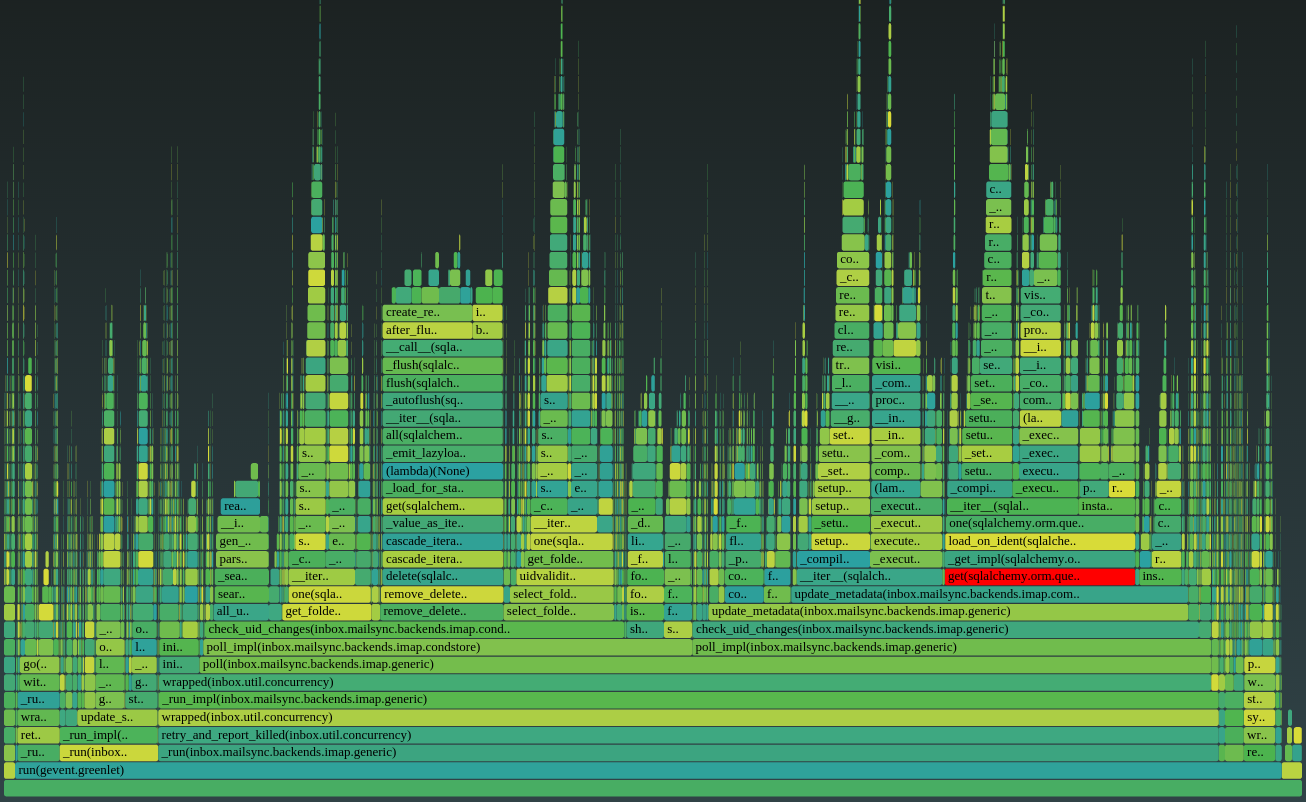
这种可视化让快速定位耗时的函数变得非常简单。例如,15% 的运行时间都被上图中高亮的 get() 函数消耗在了执行数据库连接上,而这一般是不必要的。这在本地测试中不明显,但现在定位和修复易如反掌。
但是只有单个 worker 进程的数据是不足以反映所有进程和实例的总体情况的。我们需要综合多个进程的堆栈跟踪数据。同时也需要一种方法来保存历史数据,因为分析器只在进程生命周期中保有这些数据。
我们使用一个收集器代理来周期性地从所有同步引擎进程(分布在多台机器上)中拉取数据,并将整体性能数据持久化到它自己的本地存储中。因为我们使用 HTTP 来提供数据,所以这非常简单;没必要在生产环境的实例中截断或者反转任何文件。
最终,我们有了一个轻量级的 web app,可以根据需要查看这些数据。要回答「我们的应用是如何消耗 CPU 时间的?」这种问题,只需要访问一个内部 URL:
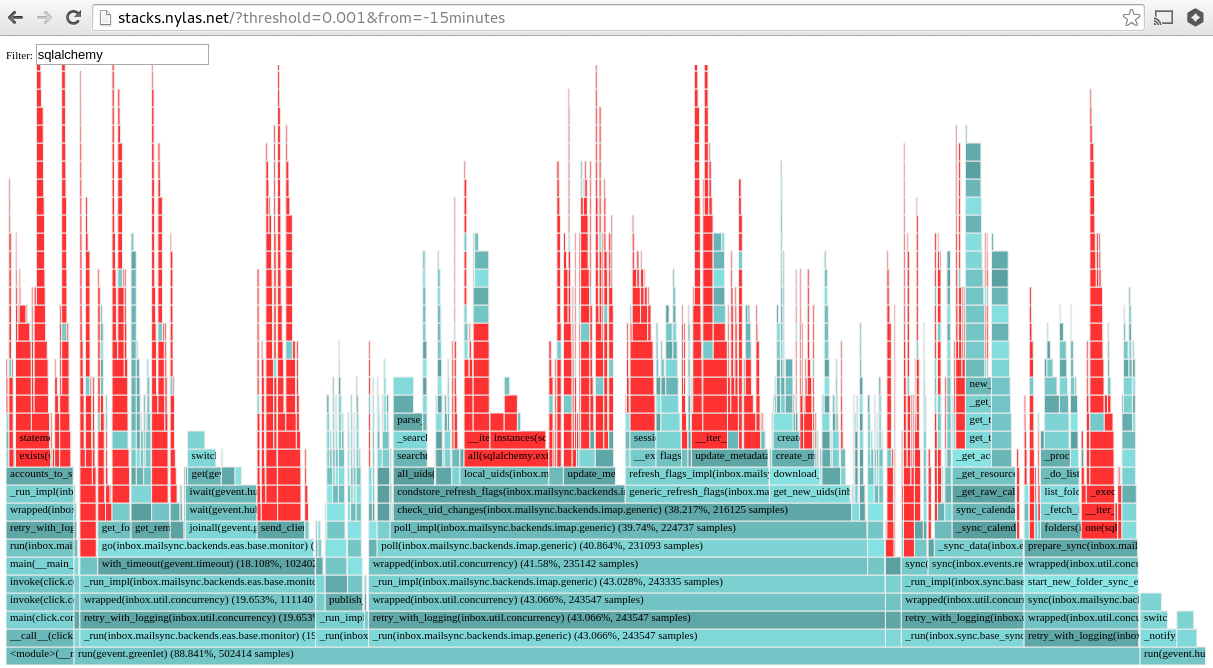
我们能为任何指定的时间间隔渲染性能数据,这样一来我们很容易就能追查到导致性能下降的原因,以及它们是何时被引入的。
所有的这些代码都在 GitHub 上开源了——去看一看,并亲身体验一下吧!
结论
部署了这种测量手段之后,定位我们托管的同步引擎的低效率部分和进行优化这些事情变得很简单。总体结果就是 CPU 负载降低了 80%。下图显示了我们发布两次卓有成效的优化补丁之后的效果。
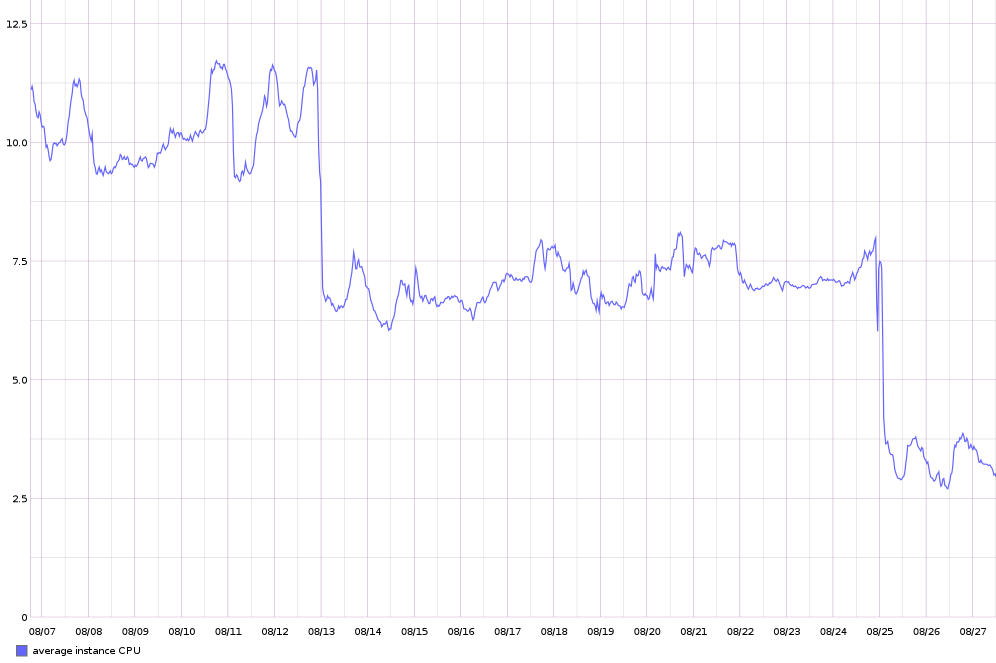
能够通过不同手段来量测和检查,对于我们服务的稳定性和高效性是至关重要的。这里简要介绍的工具只是 Nylas 更大的检测设施的一部分。我们希望在将来的文章中介绍它的更多内容。